AWS Lambda $LATEST is dangerous
AWS Lambda has supported function versions since October 2015, only
a couple of months after the service itself was publicly launched. Versions are
an optional feature - you can develop and use Lambda functions without versioning,
in which case you are working with the implicit $LATEST version.
It has been my experience that most developers don't use function versions. Some "evidence" of this is:
- The AWS CDK has a bug that can make working with versions a hassle.
- The AWS SAM transform has had similar bugs in the past.
- CloudFormation's
AWS::Lambda::Versionis too difficult to use on its own without relying on one of the previous two tools to do it automatically for you.
But is not using function versions a problem? I think so.¶
Let me explain the problem by way of an example that quite a few developers will find surprising. Look at the following diff of a simple change to fix a typo in an environment variable's name:
--- a/cfn.yml
+++ b/cfn.yml
@@ -1,20 +1,20 @@
Transform: AWS::Serverless-2016-10-31
Resources:
Function:
Type: AWS::Serverless::Function
Properties:
Runtime: python3.8
Handler: index.handler
CodeUri: ./
Environment:
Variables:
- TABLE_NAM: example
+ TABLE_NAME: example
Policies:
DynamoDBReadPolicy:
TableName: example
Events:
Api:
Type: HttpApi
Outputs:
ApiUrl:
Value: !Sub https://${ServerlessHttpApi}.execute-api.${AWS::Region}.amazonaws.com
diff --git a/index.py b/index.py
index 7f95be8..617824a 100644
--- a/index.py
+++ b/index.py
@@ -1,8 +1,8 @@
import os
import boto3
dynamo = boto3.client('dynamodb')
def handler(event, context):
- table_name = os.environ["TABLE_NAM"]
+ table_name = os.environ["TABLE_NAME"]
return dynamo.get_item(TableName=table_name, Key={"PK": {"S": "key"}})
Super simple, right? If I deploy this change on a busy API, would you expect any problems? Remember: the app was working before and it will continue working after the deployment is complete. But could there be any temporary issues?
(some time to think)
If you anticipated problems, you were right. (Though I suppose this would be a very anti-climactic blog had there been none). Here are the results of a load test (courtesy of the pretty great free tier on loader.io):
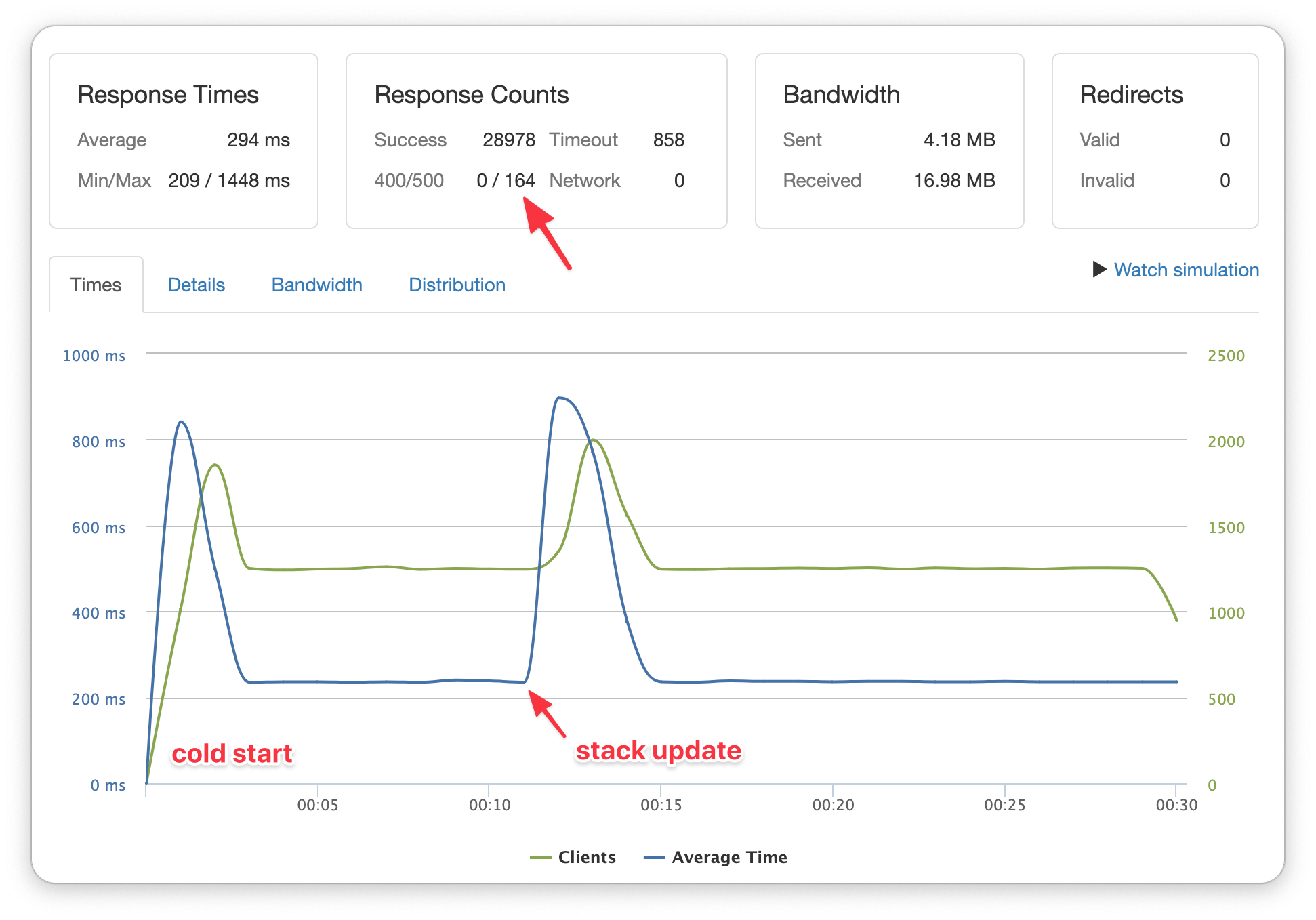
There were 164 errors returned - all during the stack update! (The timeouts were unrelated, because I had set them way too low during this example.) And what was the cause of those errors? Here's what the logs say:
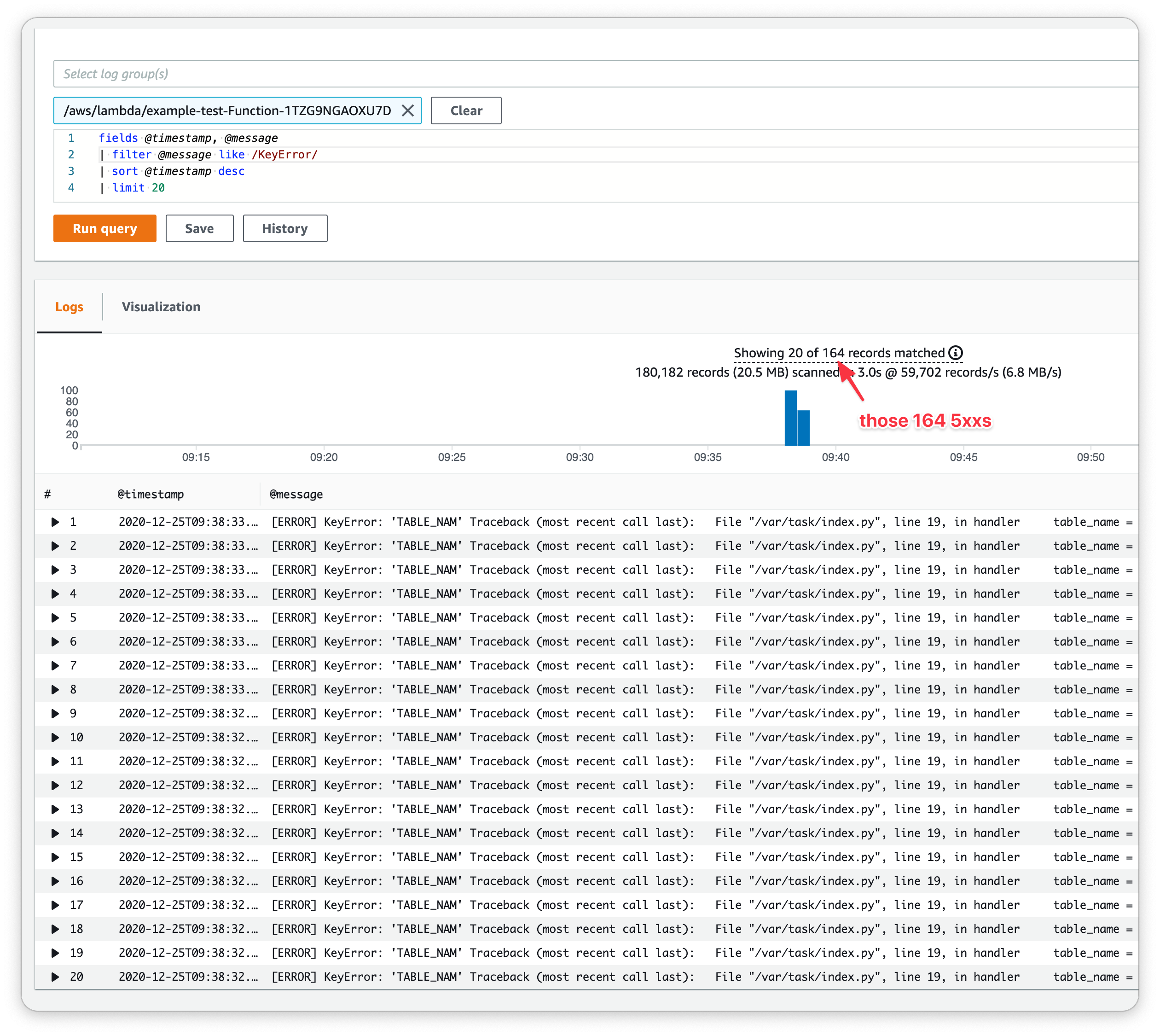
There were 164 times where the Python code failed to find the TABLE_NAM
environment variable. The only way this could happen is if the function's env
vars changed before the code did - and that's exactly what happened.
Why does CloudFormation update the env vars and the code separately? Because it
doesn't have a choice. The Lambda service exposes two APIs:
UpdateFunctionCode and UpdateFunctionConfiguration.
CloudFormation needs to call both these APIs in order to apply the changes we've
requested. And no matter which order it calls them in, there's going to be some
small window of time when one has taken effect and the other has yet to.
This problem is intractable1 if you are not using function versions.
So how do versions help?¶
Function versions are an immutable "snapshot" of a function's code and configuration.
Creating a version by itself doesn't help, you also need to use those versions. In
other words, $LATEST is best always avoided.
In the earlier example, using versions is as simple as adding AutoPublishAlias: live
to the function resource. This will automatically create a new version whenever
the function's code or configuration changes. What's more, the auto-generated
API Gateway will automatically use those automatically created versions. (We'll
get to aliases in a moment.)
For the AWS CDK, it would instead look a bit like:
const fn = new lambda.Function(this, 'Function', {
runtime: lambda.Runtime.PYTHON_3_8,
handler: 'index.handler',
code: lambda.AssetCode.fromAsset('./')
});
// instead of this:
// const integration = new int.LambdaProxyIntegration({handler: fn});
// do this:
const integration = new int.LambdaProxyIntegration({handler: fn.currentVersion});
const api = new apigw.HttpApi(this, 'Api', {});
api.addRoutes({path: '/', integration: integration});
This will configure the API Gateway to call lambda:Invoke with an ARN of
arn:aws:lambda:<region>:<account id>:function:FunctionName:3 instead of one
without the :3 prefix. That :3 auto-increments whenever the function's code
or configuration changes. Now you will never see those 5xx errors again!
Back to aliases. While the above works, it's a little lame because every code change means updating the API Gateway too - which means waiting an extra second or so in the stack update. Instead we can use aliases. An alias is a way of creating a name that points to a version - and the version it points to can change. Think of the relationship between aliases and versions as similar to the relationship between branches and commits in Git. If our code instead had these lines:
const alias = fn.currentVersion.addAlias('live');
const integration = new int.LambdaProxyIntegration({handler: alias});
then API gateway would invoke arn:aws:lambda:<region>:<account id>:function:FunctionName:live.
Now the API Gateway doesn't need to be updated on every code change, plus a few
other benefits.
Summary¶
You should always use function versioning. You should almost always2 use function aliases. Aliases have a handful of benefits involving metrics in CloudWatch, IAM permissions, traffic-shifting, etc. that are too big a topic for this post.
1 Yes, you could write your code to look for either environment variable in this contrived example - but it can apply to any configuration and code changes. E.g. EFS mounts changing, layers changing, runtime changing, etc. I would argue that coding defensively to prevent this scenario instead of just using versions is an ineffective use of time.
2 An example scenario of where you might want to use function versions
and not aliases (and not $LATEST either) is in Step Function definitions. If you
have version N of a step function mid-execution when you do a deployment, you
might not want version N+1 of the Lambda functions in the subsequent states to
receive outputs from version N functions. This way you can ensure that the entire
step function definition (state machine, Lambdas and all) is immutable for all given
executions.