Cursory AWS KMS research
A couple of months ago, Thai Duong wrote an interesting post about
problems with the AWS Encryption SDK. Most of it goes way over my head, but my
curiosity was piqued by the mention of reverse-engineering the format of the
"ciphertext" returned by KMS Encrypt. There wasn't much detail on
that (it wasn't the primary topic) so I thought I'd do some digging into it.
I haven't dug into this too much, but I thought I'd share what I have so far as I've yet to find any other resources on this. My hope is that someone else is able to build upon this and publish something much more useful and interesting.
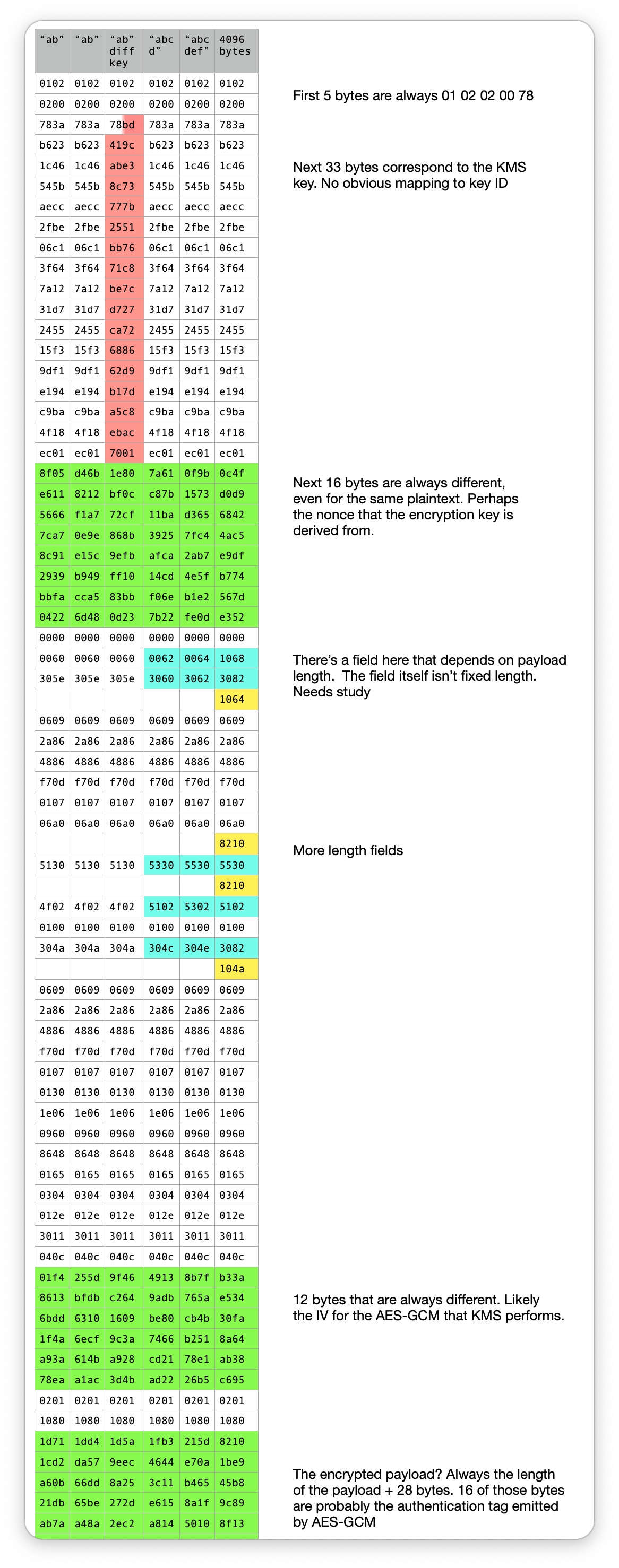
Some points worth calling out, in no particular order:
-
I was surprised by how much "overhead" there is, i.e. how many bytes there are that I can't seem to change. There's at least 52 bytes that don't change, regardless of plaintext, key ID, region or encryption context.
-
The bytes that change with the key ID are 33 bytes long. They appear to be entirely random. A key ID is 16 bytes. An account ID is 12 decimal digits. I'm not yet sure if this is decipherable.
-
Of the fields that change on every response, there are three. One is 16 bytes, one is 12 bytes and the other is the length of the plaintext + 28 bytes. The 12 byte field is likely the 96-bit IV used for the AES-GCM algorithm that KMS performs. I think that part of the 28 bytes is the 16 byte authentication tag emitted by AES-GCM. And the 16 byte field is the nonce used to derive the data encryption key using SP800-108 as per the KMS docs. But I really don't know what I'm talking about.