How ima.ge.cx works
This article has been in my drafts for 380 days. It's probably time I published it,
before I forget even more details about how it works. ~A few~ 380+ days ago, I
published ima.ge.cx. It's a web frontend for browsing the contents
of Docker images. It's like a less powerful version of dive that
doesn't require you to pull images locally. It's also worth noting that there's
a much more feature-rich (and likely less buggy) site that does a similar thing:
Registry Explorer.
I planned on cleaning up the code significantly before publishing (I can't have anyone see how the sausage is made), but in the year since writing it I have lost all context and motivation to do so. In an act of personal growth, I have pushed the code to GitHub in its incomplete state. There are deep link references to specific functions below. But first, here's a rough rundown of how it works. First, an architecture diagram:
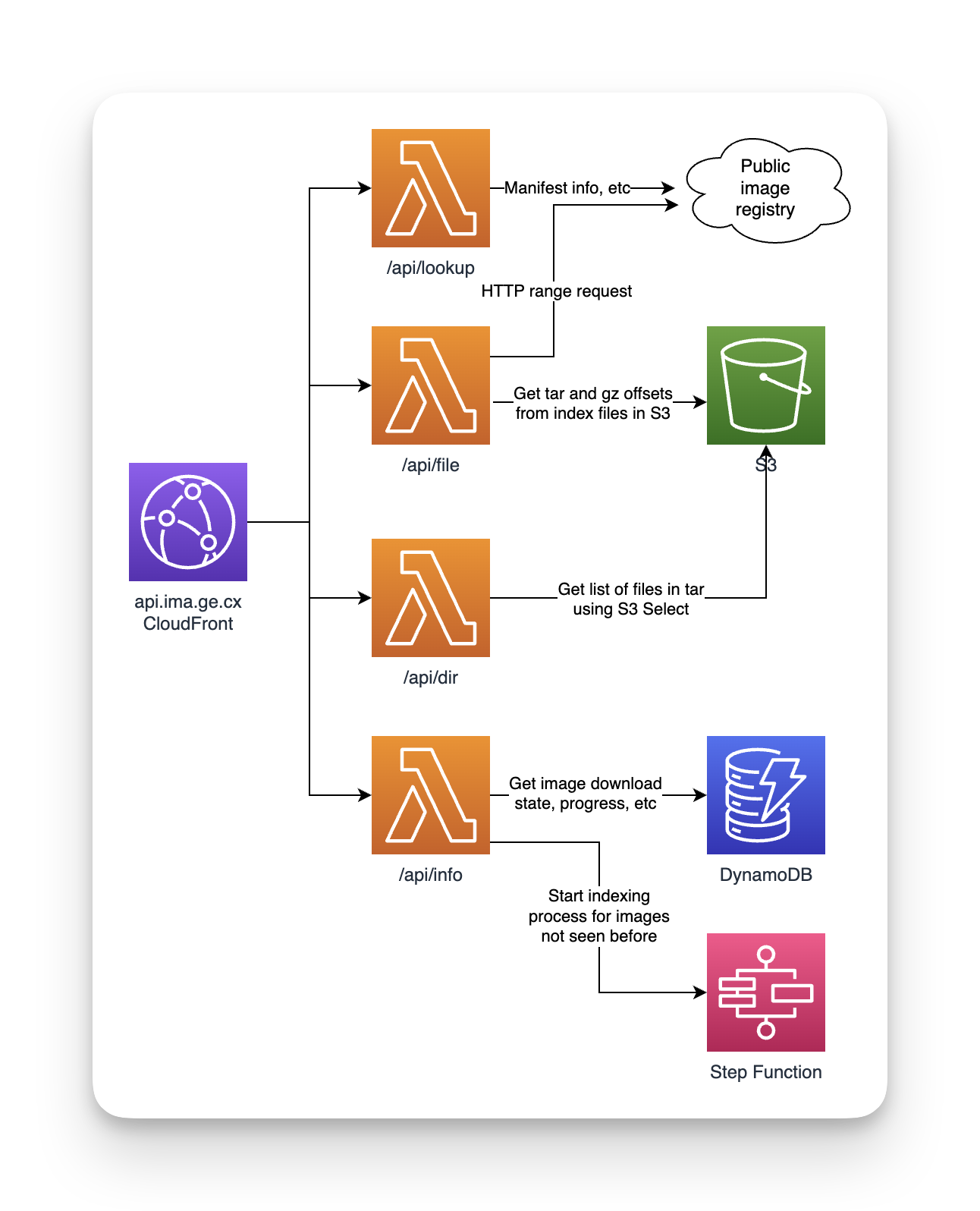
And here's a screenshot of the workflow diagram from the Step Functions console:
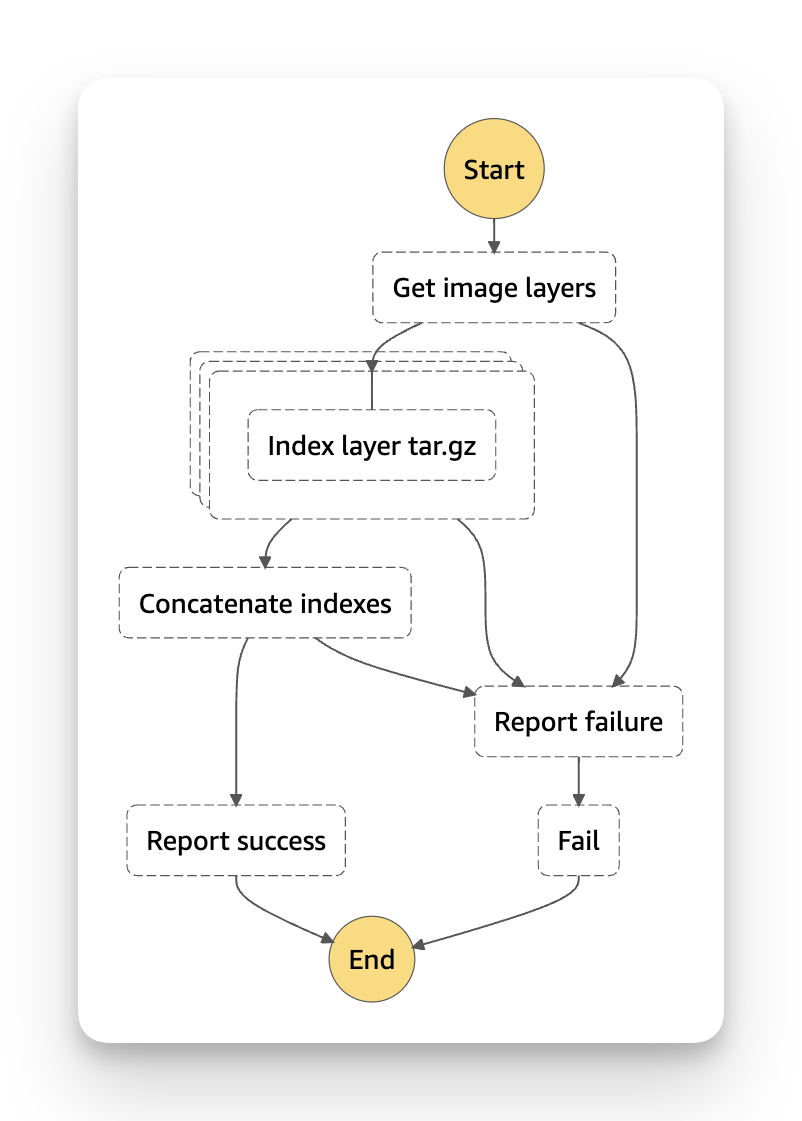
Image indexing¶
When an image hasn't yet been indexed, a Step Function execution is started. The input to that execution is:
{
"Repo": "mcr.microsoft.com/dotnet/sdk",
"Digest": "sha256:d775c8f5267a84304e601702c37b0c416ba9813e72d16d0ee3e70e96323ee624"
}
The first task (Get Image Layers) contacts the registry and returns a list of digests for all the layers in the image.
The second task is a Map state over those layers. The Index layer tar.gz task
is invoked concurrently for each layer in the image. The input to that task is:
{
"Repo": "mcr.microsoft.com/dotnet/sdk",
"Digest": "sha256:d775c8f5267a84304e601702c37b0c416ba9813e72d16d0ee3e70e96323ee624",
"Layer": "sha256:2f2ed1ba8f71764331c67cd10a338c6ed607e5c173b056ec69fbe592389fc33a"
}
That Lambda function does the following:
- It downloads the layer tar.gz blob from the registry
- Streams the tar.gz stream to
gztoolvia stdin - Reads the tar archive from
gztool's stdout - Records the metadata and offset for each file in the tar stream
- Uploads the gz index generated by
gztoolto S3 ats3://bucket/sha256:$layer/index.gzi - Uploads the tar index as a newline-delimited JSON doc to S3 at
s3://bucket/sha256:$layer/files.json.gz
The next task in the workflow is Concatenate indexes, which combines all the
files.json.gz layer-specific indexes into a single file. We do this so we only
have one file to query at read-time. Here's an excerpt of a few lines from that
concatenated file (pretty-printed for readability):
{
"Offset": 100097024,
"Spans": [
10
],
"Hdr": {
"Typeflag": 48,
"Name": "opt/teamcity/webapps/ROOT/WEB-INF/lib/spring-security.jar",
"Linkname": "",
"Size": 2545358,
"Mode": 33188,
"Uid": 1000,
"Gid": 1000,
"Uname": "",
"Gname": "",
"ModTime": "2022-10-27T09:46:58Z",
"AccessTime": "0001-01-01T00:00:00Z",
"ChangeTime": "0001-01-01T00:00:00Z",
"Devmajor": 0,
"Devminor": 0,
"Xattrs": null,
"PAXRecords": null,
"Format": 2
},
"Parent": "opt/teamcity/webapps/ROOT/WEB-INF/lib/",
"Layer": "sha256:30175d9c0a53916cd46e92a1f59c48406e6fa7690889342829a7636745756f23"
}
{
"Offset": 102643200,
"Spans": [
10,
11
],
"Hdr": {
"Typeflag": 48,
"Name": "opt/teamcity/webapps/ROOT/WEB-INF/lib/spring-webmvc.jar",
"Linkname": "",
"Size": 2661280,
"Mode": 33188,
"Uid": 1000,
"Gid": 1000,
"Uname": "",
"Gname": "",
"ModTime": "2022-10-27T09:46:58Z",
"AccessTime": "0001-01-01T00:00:00Z",
"ChangeTime": "0001-01-01T00:00:00Z",
"Devmajor": 0,
"Devminor": 0,
"Xattrs": null,
"PAXRecords": null,
"Format": 2
},
"Parent": "opt/teamcity/webapps/ROOT/WEB-INF/lib/",
"Layer": "sha256:30175d9c0a53916cd46e92a1f59c48406e6fa7690889342829a7636745756f23"
}
{
"Offset": 105305088,
"Spans": [
11
],
"Hdr": {
"Typeflag": 48,
"Name": "opt/teamcity/webapps/ROOT/WEB-INF/lib/spring.jar",
"Linkname": "",
"Size": 5050699,
"Mode": 33188,
"Uid": 1000,
"Gid": 1000,
"Uname": "",
"Gname": "",
"ModTime": "2022-10-27T09:46:58Z",
"AccessTime": "0001-01-01T00:00:00Z",
"ChangeTime": "0001-01-01T00:00:00Z",
"Devmajor": 0,
"Devminor": 0,
"Xattrs": null,
"PAXRecords": null,
"Format": 2
},
"Parent": "opt/teamcity/webapps/ROOT/WEB-INF/lib/",
"Layer": "sha256:30175d9c0a53916cd46e92a1f59c48406e6fa7690889342829a7636745756f23"
}
Image reading¶
Directory contents¶
GitHub link. When enumerating the filesystem of an image, the
/api/dir function uses S3 Select to return only parts of the file.
The SQL query is SELECT * FROM s3object s WHERE s.Parent = '%s', which causes
S3 to only return the JSON lines for files in that particular directory. Using
S3 Select instead of downloading the whole file into memory means that the Lambda
function won't slow down or crash when processing the contents of giant Docker images.
File contents¶
GitHub link. When returning the contents of a specific file, the
/api/file function uses S3 Select again. This time the query is SELECT * FROM s3object s WHERE s.Hdr.Name = '%s'.
This determines which layer gzindex needs to be downloaded and fed back into
gztool. gztool then tells us the range of the compressed bytes that we need
to download from the Docker image registry (via a HTTP range request). After
downloading that byte range, we feed the compressed bytes back into gztool and
it returns the uncompressed file contents - which get returned back to the client.
Parting thoughts¶
- I should have finished this blog post while it was still fresh. It's hard to blog about code you don't remember writing.
- Frontend UIs are so hard. Being unable to build a nice frontend for this project drained almost all my enthusiasm to see it through to the end.
- Serverless is really nice. Step Functions and Lambda will scale out as much as needed when an image needs to be processed and scale back to zero when the site isn't being used - which is most of the time. If I had to pay a few dollars a month to run a VPS for this project, I would have turned it off long ago. I don't think this project has even cracked the $1 threshold in the last year it's been online.
- S3 Select is a great service, but I've never heard of anyone using it. One surprising gotcha was that it returns results in chunks, but they're not necessarily aligned with the ends of lines - so you need to buffer the results and then parse those line-by-line. Here's a function I wrote for that.
- The absolute highlight of working on this is that it lead to getting in touch with Jon Johnson. He's a very smart guy and I am honoured to have played my part in his enthusiasm for gzip.